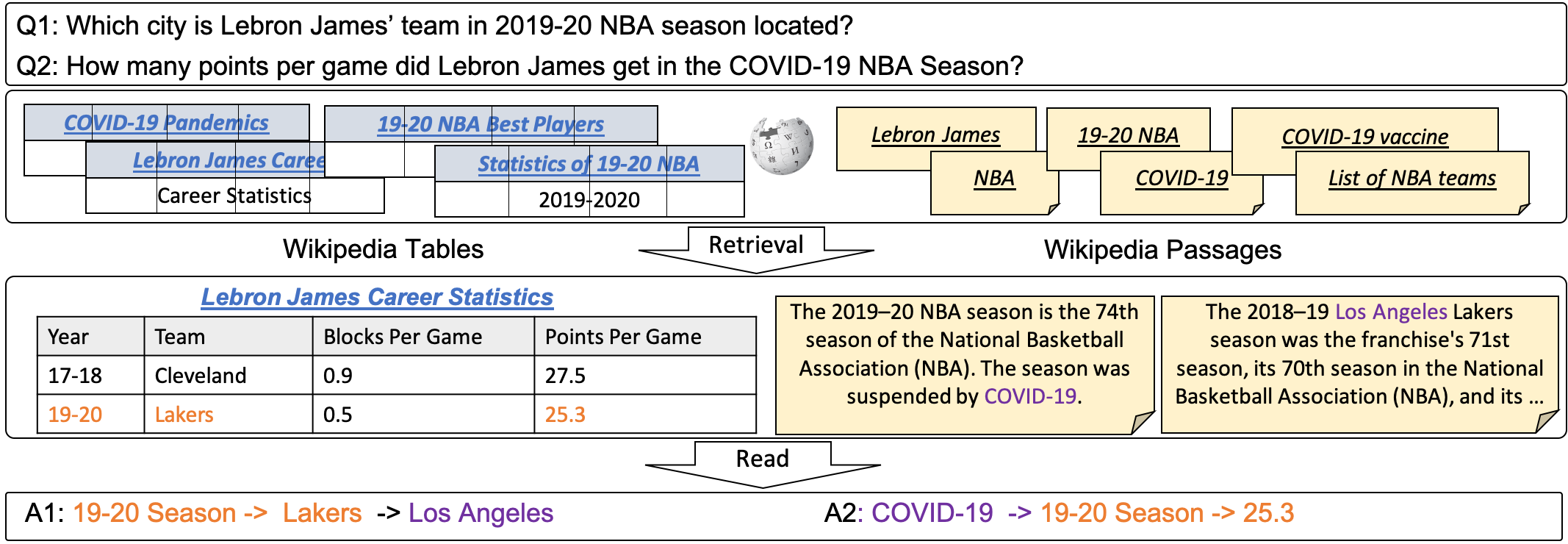
Why OTT-QA Answering?

HIGH-QUALITY
Mechanical Turk;
Strict Quality Control

LARGE-SCALE
400K Wikipedia Tables;
5M hyperlinked passages;
45K natural questions.

HYRBID
Semantic Understanding;
Symbolic Reasoning.

Retrieval
Retrieve over the whole Wikipedia